Digital Journal for Philology
Stefan
Descher
Göttingen
Merten
Kröncke
Göttingen
Simone
Winko
Göttingen
Wie plausibilisieren Literaturwissenschaftler*innen ihre Interpretationen?
Das DFG-Projekt »Das Herstellen von Plausibilität in Interpretationstexten. Untersuchungen zur Argumentationspraxis in der Literaturwissenschaft« (ArguLit)
Interpret*innen literarischer Texte möchten die von ihnen vertretenen Thesen möglichst plausibel machen. Aber was heißt das eigentlich? Wie gehen Interpret*innen vor und welche Mittel setzen sie ein, um dieses Ziel zu erreichen? Das DFG-Projekt »Das Herstellen von Plausibilität in Interpretationstexten. Untersuchungen zur Argumentationspraxis in der Literaturwissenschaft« (ArguLit) erforscht anhand von literaturwissenschaftlichen Interpretationen, die zwischen 1995 und 2015 in philologischen Fachpublikationen erschienen sind, welche Strategien in Interpretationstexten eingesetzt werden, um interpretative Thesen zu plausibilisieren.
Die beiden Teilkorpora setzen sich aus Interpretationen zu zwei kanonischen und vielinterpretierten Erzähltexten der deutschen Literatur zusammen: Annette von Droste-Hülshoffs Die Judenbuche und Heinrich von Kleists Michael Kohlhaas. Das Projekt soll dazu beitragen, genauere Kenntnisse über eine besonders wichtige und offenkundig funktionierende, aber kaum erforschte Praktik des Erzeugens und Vermittelns von Wissen in der Literaturwissenschaft zu gewinnen und implizite Regeln offenzulegen, die fach- oder bereichsspezifisch gelten. Wir möchten es hier in Grundzügen vorstellen (Korpus, Analyseverfahren, exemplarische Ergebnisse), ohne dabei jedoch ins Detail gehen zu können. Die vollständigen Ergebnisse des ArguLit-Projekts werden in naher Zukunft in monographischer Form veröffentlicht. Die gesamte Studie ist im Open Access verfügbar. Informationen zum Download finden sich unter www.argulit.uni-goettingen.de.
Untersuchungskorpus
Das Untersuchungskorpus bilden 93 deutschsprachige Interpretationstexte zu Kleists Michael Kohlhaas und Droste-Hülshoffs Die Judenbuche. Alle Korpustexte wurden digitalisiert, so dass sie quantitativ ausgewertet und digital annotiert werden können. Da es um die gegenwärtige Argumentationspraxis geht, wurde das Korpus aus Beiträgen der letzten 20 Jahre zusammengesetzt (1995–2015), bezogen auf die Vorbereitungsphase des Projekts. Die Kanonizität der interpretierten Erzählungen sichert eine Vielzahl theoretischer Zugriffe. Es wurden verschiedene Publikationstypen berücksichtigt (Aufsätze in Zeitschriften, Jahrbüchern und Sammelbänden sowie Kapitel in Monografien), um in diesem Punkt die Breite des Faches abzubilden. Für die Auswahl wurde das Kriterium fachlicher Qualitätsprüfung eingesetzt: Einbezogen wurden Interpretationstexte, die mindestens einen der Prozesse literaturwissenschaftlicher Qualitätssicherung durchlaufen haben (peer review, Begutachtung bei Dissertationen, Veröffentlichung in literaturwissenschaftlichem Fachverlag etc.). Während sämtliche 93 Korpustexte für allgemeine quantitative Analysen herangezogen wurden (z. B. Textlänge, Vorkommen bestimmter Begriffe, Einsatz von Zitaten etc.), wurden 58 von diesen Interpretationen (je 29 zur Judenbuche bzw. zu Michael Kohlhaas) einer sehr detaillierten und aufwändigen, sowohl hermeneutischen als auch quantitativen Analyse unterzogen. Das Verfahren wird im Folgenden skizzenartig vorgestellt.
Analyseverfahren
Ausgehend von der Annahme, dass zum Plausibilisieren sowohl die argumentativen Beziehungen zwischen Aussagen als auch die gewählten Darstellungsmittel beitragen, bestand das Analyseverfahren aus zwei grundlegenden Schritten: (1) der Rekonstruktion der argumentativen Gesamtstruktur einer Interpretation sowie (2) der leitfadengestützten Erfassung und Untersuchung von Darstellungsphänomen (beispielsweise Techniken der Leser*innenlenkung, der Art und Weise des Primärtext- und Forschungsbezugs usw.).
Rekonstruktion von Argumentbäumen
Jeder der 58 Korpustexte wurde im 4-Augen-Prinzip Satz für Satz daraufhin analysiert, welche Aussagen eine argumentative Funktion haben, das heißt welche ein Argument oder eine zu begründende These darstellen. Die im Regelfall sehr komplexe Gesamtargumentation, die mitunter Argumente im dreistelligen Bereich umfassen kann, wurde in Form von ›Argumentbäumen‹ visualisiert, wie Abbildung 1 exemplarisch zeigt.1 Die Inhalte der Kästen sind in dieser Grafik nicht erkennbar, es kommt uns an dieser Stelle lediglich darauf an, einen Eindruck vom Aufbau und von der Funktionsweise der Argumentbäume zu geben:
Die ›Bäume‹ bestehen aus einzelnen Kästen, in denen sich jeweils Aussagen des Interpretationstexts befinden (ggf. in Reformulierung). Die Kästen sind vertikal auf verschiedenen Ebenen angeordnet und durch Linien miteinander verbunden, die Begründungsrelationen anzeigen: Eine Aussage auf einer unteren Baumebene begründet jeweils eine Aussage auf einer höheren Ebene, wenn beide Aussagen (Kästen) durch eine Linie miteinander verbunden sind. Die sich so ergebenden Begründungsketten gipfeln typischerweise in einer, gegebenenfalls auch mehreren Hauptthese(n), die im Baum blau markiert werden. Alle auf diese Weise erfassten Argumente wurden zudem inhaltlich klassifiziert: Es wurden 28 Argumenttypen voneinander unterschieden, zum Beispiel Argumente, die Aussagen über den Primärtext, über Forschungsbeiträge, über biographische, historische und andere Sachverhalte machen und so weiter. Mithilfe der so erstellten Argumentbäume ist eine Vielzahl statistischer Auswertungen möglich. Exemplarische Ergebnisse stellen wir unten vor.
Leitfaden, digitale Annotation und quantitative Auswertung
Neben der rein argumentativen Struktur tragen auch weitere Faktoren – etwa Darstellungsstrategien, die interne Kohärenz herstellen und fachliche Akzeptanz sichern sollen – zur Plausibilisierung bei. Zur Erfassung solcher weiteren Faktoren diente ein umfangreicher tabellarischer Leitfaden, in dem potenziell relevante Textmerkmale manuell dokumentiert wurden. Dazu gehören unter anderem Informationen zu Metadaten (z. B. Publikationskontext, Karrierestufe der Verfasser*innen), zu den allgemeinen Interpretationszielen, zu theoretischen Hintergrundannahmen (z. B. den herangezogenen Theorien, den eingesetzten Schlussregeln und Topoi), zum Umgang mit Forschung (z. B. Wie viele Forschungstexte werden erwähnt? Wird ein Forschungsüberblick gegeben? Gibt es eine argumentative Auseinandersetzung mit der Forschung? usw.), zu generellen strukturellen Merkmalen oder rezeptionssteuernden Darstellungstechniken (z. B. Wird der Aufbau explizit vorgestellt? Werden die Ergebnisse am Ende zusammengefasst? usw.) oder rhetorischen Auffälligkeiten.
Einige Textmerkmale wurden zusätzlich mithilfe von CATMA2 digital annotiert, etwa Vertextungsmuster (vereinfacht gesagt: In welchen Passagen des Interpretationstexts wird primär etwas erklärt, wo wird primär etwas beschrieben, wo wird primär argumentiert, wo gibt es ggf. narrative Elemente?), die Position der Hauptthesen im Interpretationstext und andere Merkmale, so dass die annotierten Texte anschließend auch quantitativ ausgewertet werden und zum Beispiel Aufschluss über typische Muster des Textaufbaus geben konnten. Sämtliche 93 Korpustexte wurden zudem auf den Einsatz potenziell argumentationsanzeigender Konnektoren wie »denn«, »da«, den Ort oder die Häufigkeit von Zitaten und anderer quantitativ erfassbarer Eigenschaften ausgewertet.
Abschließend seien, gewissermaßen als ›Vorschau‹ auf die monografische Publikation, einige exemplarische Projektergebnisse vorgestellt. Die ausführliche Erläuterung und Kommentierung dieser Ergebnisse ist der Publikation vorbehalten.
Exemplarische Ergebnisse
Ergebnis 1: Primärtextbezug spielt beim Argumentieren für Interpretationshypothesen die quantitativ größte Rolle
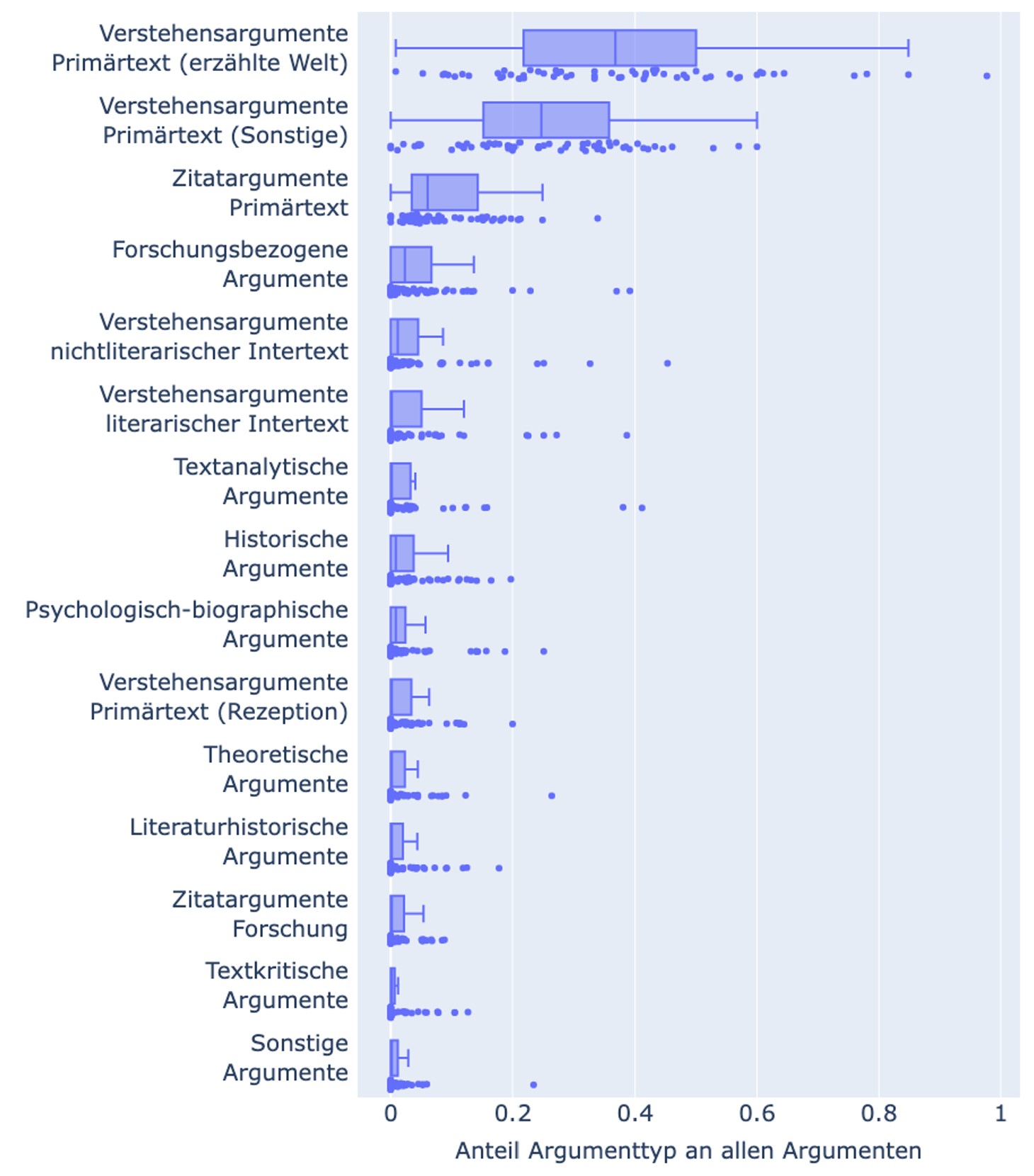
Von den insgesamt 5158 rekonstruierten Argumenten sämtlicher Korpustexte sind – gemittelt über die untersuchten Korpustexte – ca. 69 % Argumente, die sich in der einen oder anderen Weise direkt auf den Primärtext beziehen (Abb. 2). Davon sind wiederum ca. 37 % Argumente, die sich auf ein Verständnis der erzählten Welt des Primärtexts beziehen; ca. 25 % Argumente, die sich auf ein Verständnis des interpretierten Textes beziehen, in dem andere textbezogene Sachverhalte als ein Verständnis der erzählten Welt zum Ausdruck kommen, zum Beispiel Zeichenbeziehungen im Text; und ca. 9 % Argumente, in denen direkt aus dem Primärtext zitiert wird. Zählt man auch Argumente hinzu, die sich auf textkritische beziehungsweise entstehungsgeschichtliche Sachverhalte, die narratologische Beschaffenheit oder vom Text ausgelöste Rezeptionsphänomene beziehen, so ergibt sich sogar ein Wert von ca. 76 % von auf den Primärtext bezogenen Argumenten relativ zur Gesamtzahl aller Argumente. Auffällig ist zudem, dass sich Primätextargumente häufiger auf den unteren Ebenen der Argumentbäume befinden, insbesondere auf der letzten Ebene. Man kann dies so verstehen, dass Primärtextbezüge häufig das ›Fundament‹ von Argumentationen für Interpretationshypothesen darstellen.
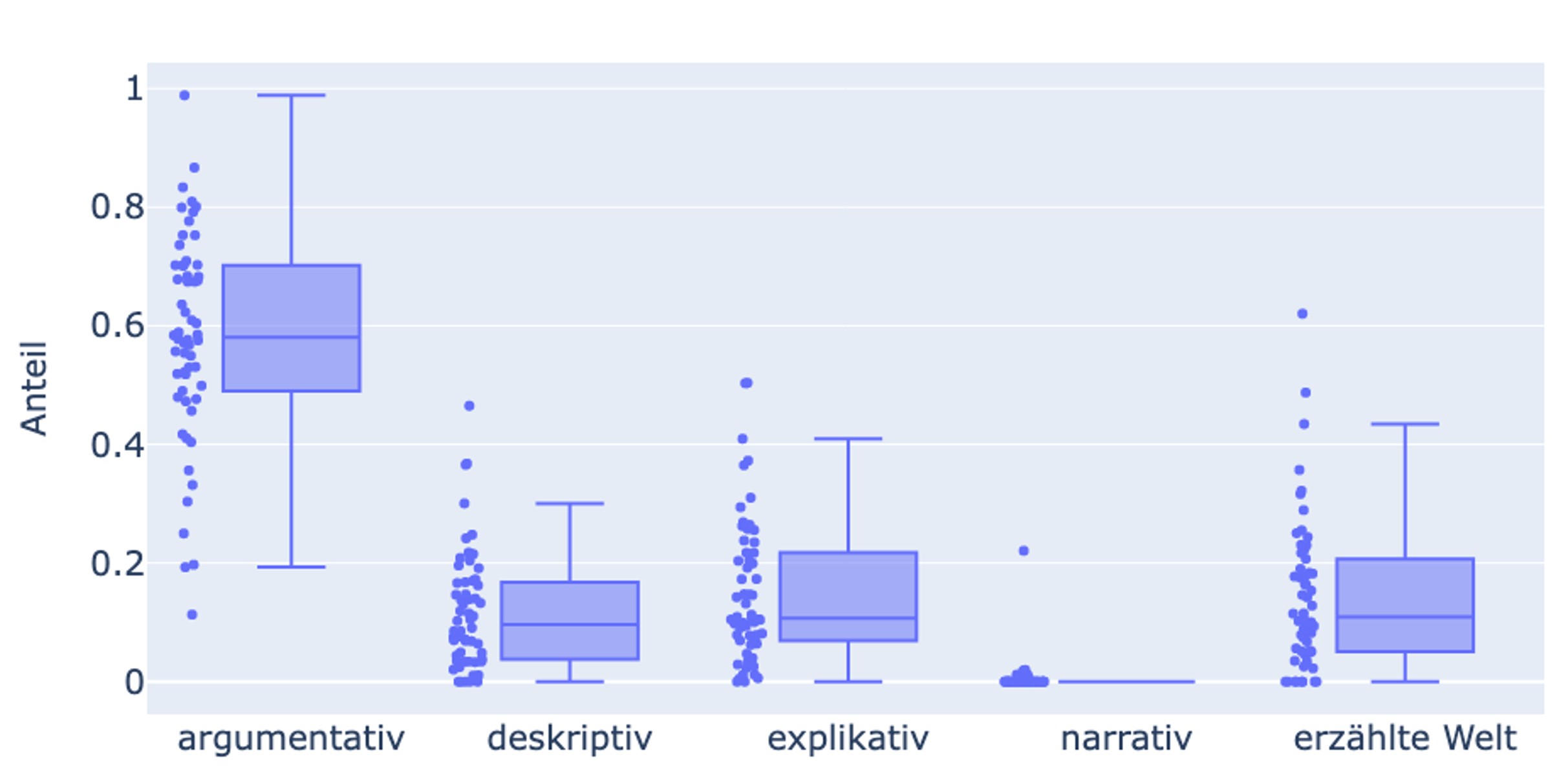
Dieser Befund, der auch vor dem Hintergrund der im Fach diskutierten Frage zu sehen ist, ob der Literaturwissenschaft ihr Gegenstand (der literarische Text) abhanden komme, wird auch dadurch bestätigt, dass die Wiedergabe der erzählten Welt, wenn auch knapp, quantitativ das zweithäufigste Vertextungsmuster nach den primär argumentativen Passagen darstellt, in den Korpustexten also vergleichsweise großen Raum einnimmt (Abb. 3).
Ergebnis 2: Nur in wenigen Korpustexten gibt es eine ausführliche argumentative Auseinandersetzung mit konkurrierenden Interpretationen
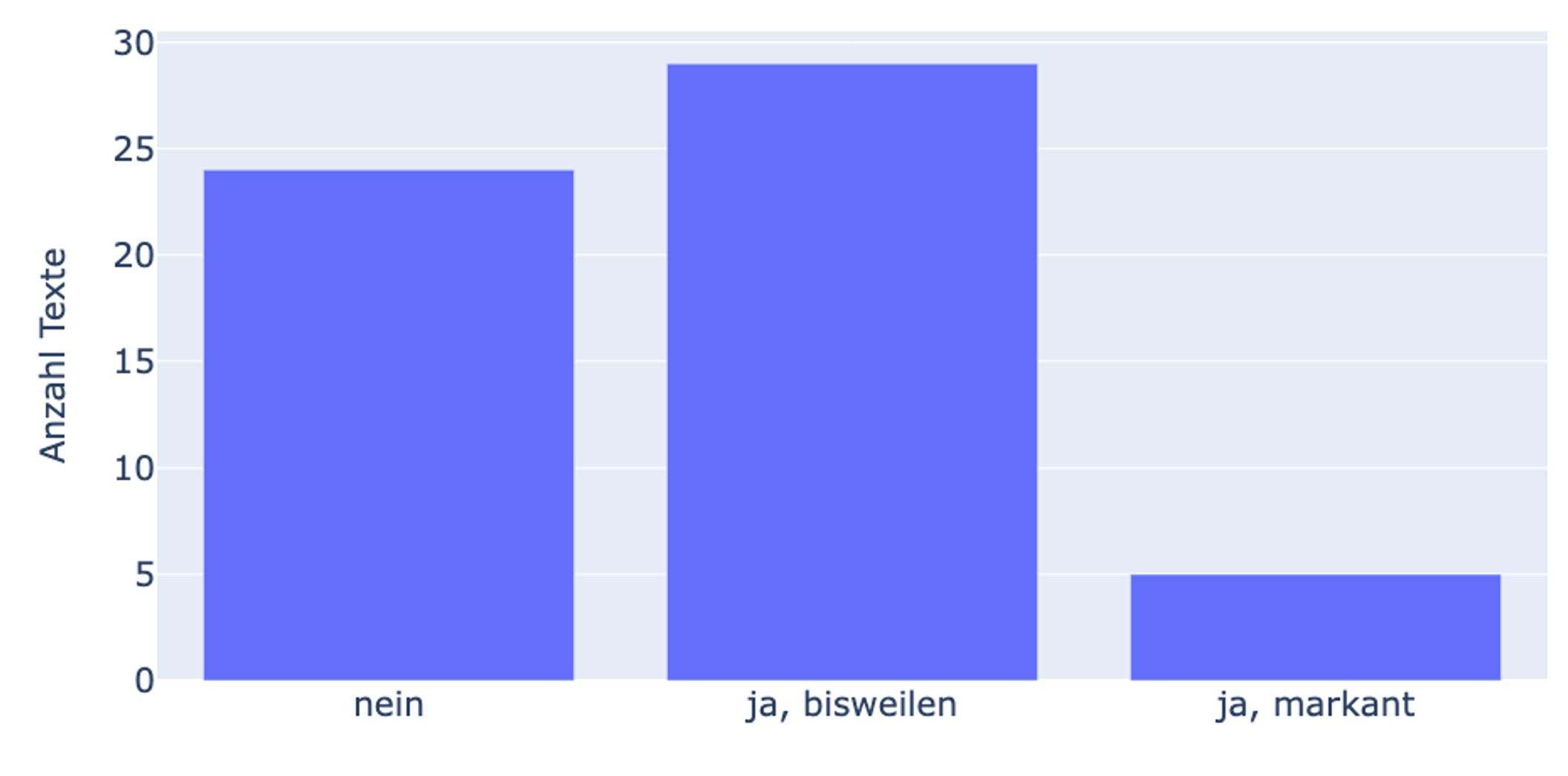
Das Projekt untersuchte auch, in welcher Weise sich Interpret*innen auf andere Forschungsbeiträge beziehen. Eine von mehreren diesbezüglichen Analysefragen lautete, wie häufig sie in die argumentative Auseinandersetzung mit anderen Beiträgen einsteigen, das heißt ob andere Forschungsbeiträge mit Gründen kritisiert oder gestützt wurden. Hier wurden drei Kategorien gebildet: (1) nein, (2) bisweilen und (3) markant.3 Wie sich zeigt (Abb. 4), ist eine markante argumentative Auseinandersetzung mit der Forschung in 5 Korpustexten anzutreffen. 29 Korpustexte setzen sich bisweilen argumentativ mit anderen Forschungsbeiträgen auseinander. In 24 Korpustexten, das heißt in über 40 % aller ausgewerteten Interpretationen, findet keine argumentative Auseinandersetzung mit der Forschung statt.
Zudem werden in 83 % aller Interpretationen keine Gegenargumente (seien diese aus der Forschung gewonnen oder von den Verfasser*innen selbst formuliert) gegen die eigene Interpretation erwogen.
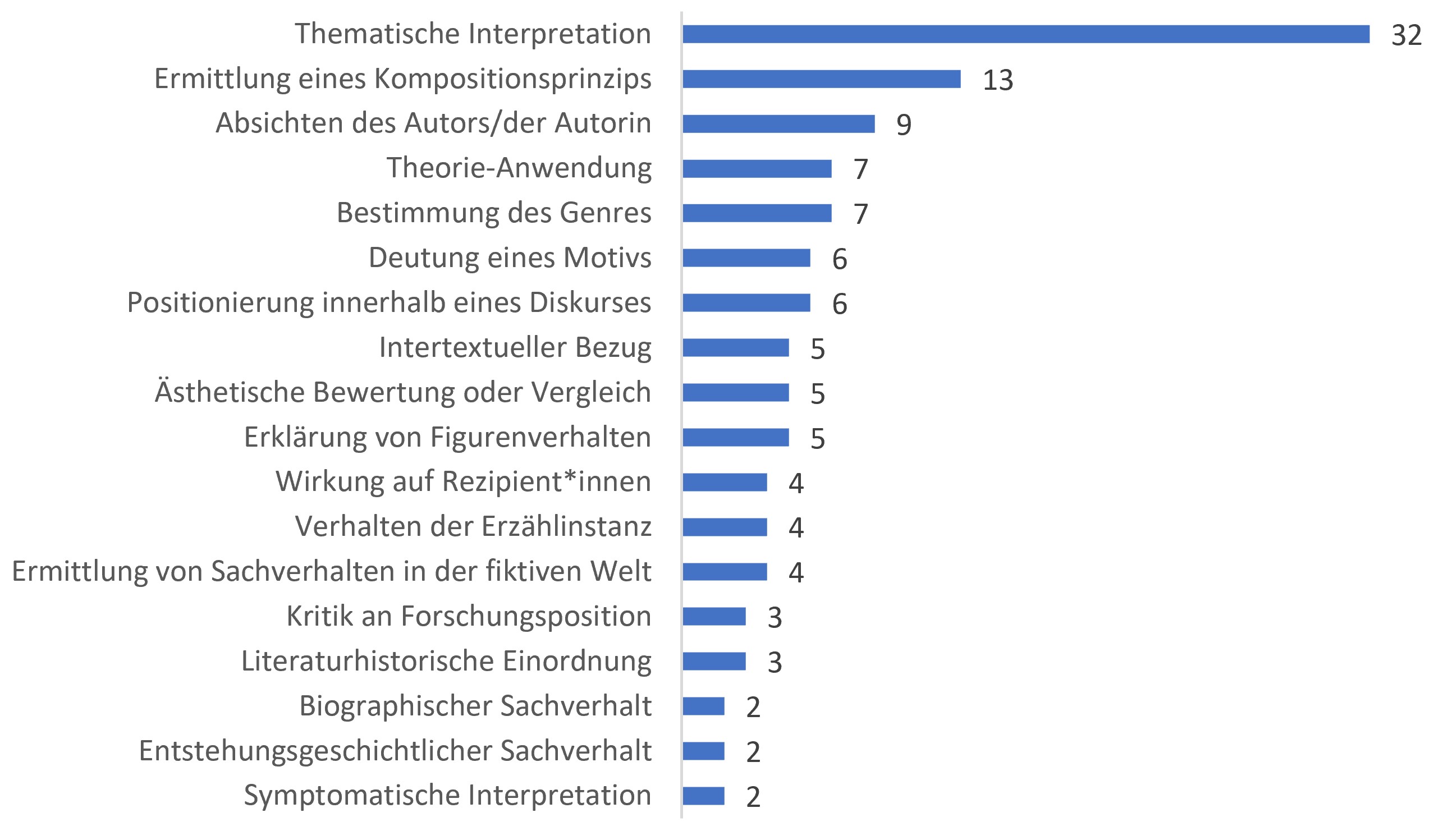
Ergebnis 3: Das häufigste allgemeine Interpretationsziel besteht in der Identifikation eines bestimmten Themas
Sämtlichen Hauptthesen, die bei der Erstellung der Argumentbäume ermittelt wurden, wurde jeweils mindestens ein allgemeines Interpretationsziel zugeordnet (z. B. Deutung eines Motivs, Bestimmung des Genres usw.). Auf diese Weise wurde eine Statistik der häufigsten Ziele erstellt, die Interpret*innen verfolgen. Dabei zeigt sich (Abb. 5), dass die Ermittlung eines Themas das mit Abstand häufigste Interpretationsziel darstellt. Anders gesagt: Viele Interpretationen zielen darauf ab, Hypothesen nach dem Muster »im Text geht es um x« (z. B. um Recht, Ökonomie, Wahrheit usw.) zu plausibilisieren. Auffällige Variationen in Bezug auf beide Teilkorpora (in Abb. 5 nicht erfasst) ergeben sich lediglich hinsichtlich des Ziels, das Textgenre zu ermitteln – ein prominentes Ziel im Rahmen der Judenbuche-Forschung, nicht aber in Interpretationen zu Michael Kohlhaas.
Wie gesagt, handelt es sich bei diesen Ergebnissen lediglich um einen kleinen Ausschnitt dessen, was im Projekt untersucht wurde. Wir laden Leser*innen dieses Textpraxis-Themenhefts dazu ein, auch einen Blick in die vollständige, frei verfügbare Monografie zu werfen, und hoffen, mit dem ArguLit-Projekt weitere Forschungen zur literaturwissenschaftlichen Praxis anregen zu können.
Projektmitglieder: Simone Winko (Leitung), Loreen Dalski, Stefan Descher, Fabian Finkendey, Merten Kröncke, Urania Milevski, Julia Wagner
- 1. Zur Visualisierung, die zugleich einen Export in digitaler und maschinenlesbarer Form erlaubt, um quantitative Auswertungen zu ermöglichen, wurde das Programm MindMup verwendet: https://www.mindmup.com.
- 2. https://catma.de.
- 3. Aus Umfangsgründen können wir diese Kategorien hier nicht ausführlich erläutern.


Add comment