Digitales Journal für Philologie
Itay
Marienberg-Milikowsky
Dan
Vilenchik
Noam
Krohn
Kobi
Kenzi
Ronen
Portnikh
Beer-Sheva, Ben-Gurion University of the Negev
An Experimental Undogmatic Modelling of (Hebrew) Literature
Philology, Literary Theory, and Computational Methods
1. The promise of operationalization
»Digital humanities may not yet have changed the territory of the literary historian, or the reading of individual texts«, wrote Franco Moretti once, in as early as 2013, in his article »Operationalizing: or, the function of measurement in modern literary theory«.1 As one of the pioneers of digital humanities in the first two decades of the current century, Moretti did not hold back from raising doubts about the achievements of the field. However, he was not the only one to subject digital humanities to critical scrutiny. The latest and most complete example of this was Nan Z. Da’s 2019 article, »The Computational Case against Computational Literary Studies«, and the acute, vibrant controversy that followed it.2 Moretti, however, was neither attacking nor defending the field, but implicitly assuming a fundamental change in its paradigmatic key concept: instead of ›digital humanities‹ – too general a concept, too broad, and far too optimistic – he calls for operationalizing– term coined by P.W. Bridgman’s Logic of modern physics (1927) – which means to focus on measurement.
Operationalizing – indeed, as Moretti admits, »an uncommonly ungainly gerund«3– is the art of using measurement in order to understand something in a way that is more than a numerical answer to a quantitative question. It can be defined as a process in which »concepts are transformed into a series of operations – which, in their turn, allow to measure all sorts of objects«; it means to build »a bridge from concepts to measurements, and then to the world«.4 Just as theoretical concepts of the natural sciences can be translated into a process of measurement (which will of course be followed by an in-depth examination), so too theoretical concepts of the humanities, and in our case literary theory. Thus, instead of imagining a revolutionary change in the entire discipline, and even in the actual mode of reading – a vision that could certainly have been implied from some of his earlier articles, including the most influential one, »Conjectures on World Literature« (2000),5– the Moretti of 2013 seems to be proposing the setting of a more modest goal:
Digital humanities may not yet have changed the territory of the literary historian, or the reading of individual texts; but operationalizing has certainly changed, and radicalized, our relationship to concepts: it has raised our expectations, by turning concepts into magic spells that can call into being a whole world of empirical data; and it has sharpened our scepticism, because, if the data revolt against their creator, then the concept is really in trouble.6
It is not difficult to see that computers are not the heroes of this statement;7 their task, which is understood only indirectly, is limited to being a means of measurement. Yet what seems even more important, and in our opinion has not received sufficient attention from digital humanities theorists and historians, is the fact that this is nothing but a further attempt in the chain of the author’s endeavor to reconcile literary theory with what can be described as (quantitative) philology. If his earlier article corresponded with Erich Auerbach’s 1953 article, »Philology and Weltliteratur«, and playfully replaced the vision of philological accuracy in legitimizing hypotheses based on distant reading (»conjectures on world literature« instead of philology and [of]), then his later article retreated slightly back in the direction of Auerbach, seeking for something concrete and stable – data, say – to challenge conjectures. From this new computational philological point of view, literary theory may be supported by the clear measurable data, but it can just as easily be tested by it – which is not bad, of course, from a perspective that does not advocate its abstract theory too dogmatically.
Based on these premises, the use of the computer in literary studies can be seen as a link between the two main intellectual traditions devoted to the study of literary texts: philology and close reading on the one hand, and the theory of literature on the other. Quantitative operationalization of critical concepts forcibly brings the two sides closer to one another: not allowing theory to continue to be too abstract – too far from the text – while at the same time showing that ›dry‹ data can fit into a larger critical framework, one located outside of the text. Therefore, we believe that focusing on measurement and its meaning may provide fertile ground for the theoretical understanding of computational literary studies: no less productive than the never-ending attempts to redefine the exact nature of reading in the digital age.
However, in a field like literary studies, measurement and operationalization do not guarantee anything either, because, as Evelyn Gius has argued, »operationalization is not a straightforward task, since many traditional theoretical concepts and terms for literary description are too vague or too abstract to allow for a straightforward formalization«.8 And if this is true of classical narratological terms – which stand at the heart of Gius’ research, and are considered perhaps to be one of the most determined branches of literary theory – it is even truer when it comes to more essentially vague concepts, which are very common in other (late) twenty century branches of literary theory. Simply put, the more vague a term is, the more difficult it becomes to operationalize it. Formulating, say, post-structuralist ideas in quantitative phrasing, seems virtually impossible. With all that being said, in addition to the fog that anyway surrounds many critical concepts – even those which are more or less defined – there is also the subjective dimension of reading and hermeneutic practice in general, which calls into question any hope of a more stable and defensible critical discourse.
2. How to Do Things with (Literary) Texts: The Case of CATMA
Measurement in itself, therefore, cannot be an exclusive solution for literary studies in the digital age. The contours of the problem are known. The above description of the state of research, and the inherent tension between computational and non-computational approaches, is not new. It is familiar to any researcher trying to bridge the gap between the two cultures in C. P. Snow’s famous formulation; it underlies the many articles and books that address the problem from a variety of diverse angles. As is often the case with such fundamental tensions, dealing with the gap has yielded many approaches. However, what else can be done?
Interestingly, most of these approaches have something in common, something that may represent distinct concepts (or distinct ways of contextualization) of measurement: They are located at different points along the axis between data-driven research and hypothesis-driven research. Approaches that prefer data-driven research, and reduce the place of the human subject in research to a minimum, are often supported by a simple fact of the current times: the fact that there is a huge amount of data that simply cannot be handled any other way. This position is typical of Jean-Baptiste Michel and Erez Lieberman-Aiden,9 for example, as well as Lev Manovich.10 The opposite approaches, which prefer the human hypothesis, of course, recognize that they are not able to cope with the current amounts of data, but usually also have no compelling interest in dealing with them. The subject of their research tends to be very different, and, typically, involves computational analysis of far less data, which – to a certain extent at least – is capable of being examined in the back-and-forth movement between close and distant reading. This approach is typical of Geoffrey Rockwell and Stéfan Sinclair,11 among others,12 but its most distinctive formulation, as far as we know, comes from the work of Jan Christoph Meister.13 Here is a key paragraph:
A computational philology that wants to advance to ›Digital Text Studies‹ cannot be concerned with driving out a person’s natural-language intelligence and their desire for ambiguity and obliging literary scholars to communicate in a restricted way with ones and zeros. Rather, its aim must be to make fruitful a fundamental tension: that between the human conceptualisation of ›text‹ as a synthetic, meaningful communication phenomenon on the one hand, and the digital conceptualisation of text as an information phenomenon on the other.14
If the text is an information phenomenon, then, ideally, the researcher can simply extract data from it – a process usually called text or data mining – data which can then be measured as needed. However, if the text is a »meaningful communication phenomenon«, connecting people (such as the [implied] author and the [implied] reader) to one another on the basis of interpretation-dependent formulated massages, then it is much more difficult to define the ›data‹ to be extracted and measured, if at all.
Meister’s work did not remain solely in the realm of theory. It has turned into a tool called CATMA (Computer-Assisted Text Markup and Analysis).15 For reasons that will become clear later in this article, this tool has provided us with food for thought on the edges of the encounter between mathematics and literature, notwithstanding the fact that the tool we are developing and working with is doing something completely different with texts. It, therefore, becomes necessary for us to extend our discussion of it a little here.
CATMA is a platform that – as the tool founder puts it – allows literary scholars to do what they have always done: to »disagree, debate, contradict one another, and even contradict ourselves«.16 As a remedy for the tension between the two concepts of the text mentioned earlier, it is designed to support »undogmatic reading«, as stated on its homepage, an idea which was described and explained by Jan Horstmann as follows:
In a literary annotation process one often does not want to make ›dogmatic‹, i.e. rigid, inflexible either-or decisions. Rather, it is at times a matter of acknowledging vagueness, polyvalence and uncertainty in the metadata in order to be able to represent the plausibility of an annotation as an interpretation of the text. Determining ground truths, securing inter-annotator agreement or arriving at gold standards is not necessarily the prime objective in this field of practice, which is why a (literary) digital annotation tool needs to offer greater flexibility.17
Thus, as a means of manual (or semi-manual) annotation, and as a means that does not compel the user into what and how to annotate, it is easy to understand that the human reader and his/her insights are the heroes of the analysis procedure manifested by this tool. The fact that the system (in its most up-to-date version 6.3) gives equivalence to ›objective‹ textual data (organized for example as a wordlist) and ›subjective‹ meta-textual data – or, simply, metadata (organized for example as a tag-list) – is the clearest embodiment of this theoretical principle, since both kinds of knowledge can be manipulated equally.18
3. Joint Projects: The Defamiliarization of Operationalization
Operationalization of human interpretation is certainly an idea which cannot be taken for granted. It is no coincidence that one of the core characteristics of CATMA, which supports a humanist-oriented user experience, is its full accessibility to a researcher who does not know how to write a single line of code (and in fact may not even know what code is). Whether it is a researcher working alone, or a team of researchers working together on a joint annotation and analysis project, the digital system provides them with significant computational help but does not impair their independence.
In practice, it relieves them of the need to cross-campus in order to find a partner with computational skills. It serves the human scholar as a kind of a ›chevruta‹ (חברותא) – an Aramaic word with a special place in the intellectual history of Jewish culture.19 In Modern Hebrew, which adopted many Aramaic words, Chevruta is both the act of learning together and the name used for the other person who takes part in this act. As a common framework for the learning of two people, it motivates each of them to challenge the other, in a way that contributes to the discussion. When everything works well, in the end, a scholastic and dialectical conversation between the two develops a better understanding of the text under examination. In a way, this is exactly what CATMA does: the system may not ask the users questions, but it certainly encourages them to rethink what they know (or think they know).20 The user may want to annotate some textual element with the help of a tag-set derived from the theory with which he or she approached the text in the first place, but the text does not always respond to this wish easily. The way the system creates a virtual space where a theory-based tag-set and a certain text are linked by the user, causes the text to challenge the user’s assumptions, requiring an updating of such tag-set (and theory), and so on. Very often, then, the first most notable contribution of CATMA to research projects that are based on it lies, in fact, in the opportunity to re-read the text in the light of the theory, and to refine the theory in the light of the text. The system thus generates defamiliarization of the text, of the theory, and of the entire research experience, but not too strong (or too distant) defamiliarization; After an easy learning process, and a short period of getting used to the way it works, CATMA is able to keep the humanist on task, relatively close to his or her comfort zone.
Many state-of-the-art computational literary studies, however, are not based on existing and accessible tools, nor on tools which are philosophically close to the world of the literary scholar, but rather require cross-disciplinary collaboration (except in those rare cases where the research is carried out by scholars with both literary and computational backgrounds). Such collaborations, by definition, often generate deeper defamiliarization: an encounter with someone who is looking at the same object of study completely differently.
Our own joint work – only a small part of which is presented here – began with an interdisciplinary encounter that actually embodied the effort, challenge, and also the pleasure of trying to walk to the other side of campus so as to build a bridge between the two cultures. One of the PIs of this project is an expert in Hebrew literature and literary theory, and curious about mathematical-algorithmic thinking; the other is an expert in algorithmics and machine learning, and curious about literary thinking. Naturally, the question with which we set out in our first meeting reflected the meeting point of our intellectual worlds; it was intentionally broad, following specifically Moretti’s idea of operationalization, while inspired by Meister’s undogmatic reading: Is it possible to translate complex literary theories into mathematical formulas?21 And if so, could these formulas be our chevruta, i.e., someone (something, in this case) that respects our humanistic point of view, while at the same time challenging it?
4. The Road Partially Taken
Of course, it was clear to us that the question needed to be narrowed down; one cannot simply talk about literary theories and mathematical formulas in the plural. It was also clear to us that the way to carry out the research was by means of a definite selection of a suitable corpus. However, since the path we have taken from the starting point of the study to the point where it stands now has been quite a long one, and quite typical of attempts at computational-humanistic integration, it will be described below in some detail, and in a narrative form that will illuminate the usually hidden sides of the research.
As a test case, we chose then to examine a concrete phenomenon in the prose of Amos Oz (1939-2018) – considered one of the greatest Israeli writers of recent generations – a phenomenon that has given rise to extensive and developed critical work in the whole of Oz scholarship. A common assumption about Oz’s literature is related to a quasi-Jungian conception associated with it, which influences the shaping of the interactions between characters. For Oz, the drama of self-discovery usually plays out in the attempt to attain a kind of unity of opposites between different forces that run through the psyche, often represented in conflict with someone close. The enemy, in Oz’s work, is not necessarily a distant and foreign person; often he or she is actually a kind of symbolic twin brother; someone who attracts the hero. Reconciliation (even if partial) with this other character, or at least the acknowledging of its existence, allows the protagonist to recognize and accept similar sides in himself – sides which are sometimes obscure – and thus constitutes a temporary stage in his process of individuation. A horizontal struggle between siblings (real or metaphorical), then, or relatives of more or less the same generation, is indeed prominent in his work, at the expense of more vertical struggles between different generations. Literary scholar Avraham Balaban has argued, for example, that this is a psycho-literary pattern that fundamentally distinguishes Oz’s literature from that of prominent Israeli writers such as Shmuel Yosef Agnon and Avraham B. Yehoshua.22
This claim is particularly apt, or so it seems, for mathematical operationalization, since interactions between characters are an aspect of the art of storytelling whose computational research has already been shown to contribute to its understanding, primarily through methods of network analysis and graph theory.23 This methodological expectation becomes even stronger, one can assume, with the possibility of placing characters’ relationships on the diachronic/historical axis of Oz writing (on the basis of comprehensive meta-data for each text), from the early novels to the later ones, or of characterizing – on the basis of measured linguistic findings – different types of love-hostility relationships which take into account personal, family, national, ideological conflicts, and more.
And yet, a fundamental challenge for this kind of operationalization derives from the vague and indirect way in which, for the most part, good literature expresses itself, as emphasized above by Meister and Gius, and as formulated as early as the 1970s in Reader-Response theory. For even if relationships of familial or social closeness, for example, can be easily identified (father, mother, brother, sister, son, friend, etc.), the emotional or symbolic charge that accompanies each is much more difficult to identify, characterize, and define; often not being expressed in certain words, but being constructed throughout the novel. How can an algorithmic reading detect »a quasi-Jungian conception« of individuation and socialization of literary characters, without relying exclusively on comprehensive interpretive human annotation?
We have regarded taking on this challenge as generally the most important part of our project, encapsulating as it does the inherent difficulty of the encounter of mathematics and literature. Methodologically, in order to maximize our chances of success, we chose to construct our network analysis by means of a computational model called word2vec, whose role and modes of operation will be explained in detail below, and which – due to its semantic sensitivity – has the potential to be a bit closer (but no more than that!) to the humanistic conception of texts. To date, however, most of the use of this model in Hebrew has focused on analyzing affinities between words based on an algorithm trained on non-poetic textual corpora, such as Twitter or Wikipedia. Against this background, our own project greatly raised both the level of linguistic and semantic complexity of the corpus being tested, as well as the level of complexity of the question being asked. Since we wanted to properly evaluate our analytical findings, our original plan was to examine them against two control groups: first to compare them with what can be learned from the analysis of texts such as Twitter and Wikipedia, and then to compare them with another artistic corpus, of another major Israeli writer, Aharon Appelfeld (1932-2018), a body of work in which the literary design of love-hate relations, and the actual and symbolic conflicts embodied within them, is very different from that of Oz.
A feasible plan, though not an easy one. Yet it turned out, that the choice of Oz and Appelfeld – which was in no case an accident24 – could facilitate the process of computational operationalization. First, because many scholars were drawn to Oz’s and Appelfeld’s work, and thus spawned a comprehensive and rich secondary literature – literature that a computational study of their work must address, in our view, if it wishes to be regarded as a link in an intellectual chain, rather than an alien from another planet. Second, because the full archives of these two authors, preserved and managed by the Heksherim Institute for the Study of Jewish and Israeli Literature and Culture at the Ben-Gurion University of the Negev, were made available to us for research – archives that include not only original works and translations, but also manuscripts, drafts, letters, and other materials. And third – and, as we will immediately see, perhaps the most important yet surprising reason – because these writers have another common feature which greatly facilitates a computational study of their work: both have been translated into English (as well as German and other languages), more than almost any other modern Hebrew writer ever. Considering the many technical and conceptual problems of the computational study of Hebrew language and literature, with its unique syntactic and morphological characteristics, still lacking many accessible and adjustable digital tools (as compared to European languages and literatures), working on translated text was something worth thinking about seriously. The fact that Hebrew language and literature is, in general, still finding its way in the digital humanities realm,25 made this decision easier., Since our research question was related to a literary aspect that is not expected to be lost in translation, we initially decided to ›bypass‹ the Hebrew language barrier through an algorithmic analysis of the work of the two writers translated into English. This strategy, while it does involve a relinquishing of the unique medium of the Hebrew language and its poetic modes of expression and goes against the working habits of those of us engaged in literature research as a profession, should nevertheless serve as a first step in assessing the project’s research potential.26
This stage, of course, was perceived by us as a temporary stage only, as we assumed that, after dealing with the translated texts, we would return to the original texts. We also assumed that the conclusions arising from this first stage might also lead to an improvement in the ability to model the Hebrew text in the original language. In this way, part of the research process should be described as a realization of a position we call ›differential computational research‹: instead of seeing the digital humanities as something generic with universal validity, or as a kind of miracle device that, with a small amount of effort, may yield beneficial results in any textual field, we should emphasize the importance of a more balanced perception; a perception that takes into account and compares different literary styles, different stages of artistic development, and different languages.
The project seemed, then, even more feasible, and indeed it was. Our aim was to examine the potential contribution of machine learning to the understanding of the extensive and prolonged work of two of the greatest exponents of Hebrew literature of the last generation – with special attention to relationships between characters – through an in-depth dialogue with the insights of scholars who had discussed their work with more traditional tools. In line with our objectives, we decided to base our research on a double examination– manual-human and algorithmic-automatic, in both the source language and its translation into English. Following our initial broad research question, the mathematical formulas were defined and guided by literary logic, and not vice versa (forcing literary logic to obey the outcomes of a machine learning algorithm).
After an initial conceptualization of the project, the novels underwent a digitization process and were then annotated and examined slowly by the literary side of the project (Marienberg-Milikowsky and Krohn), and at the same time, the algorithmic side of the project (Vilenchick, Kenzi and Portnikh) began to build and train a suitable computational model. But after a few novels and many discussions, we discovered that we had something much more interesting at hand27 – something that will be described below, and which touches more substantially (and, no less important: more universally) on the point from which we set out, that is, the encounter between mathematics and literature in a unified hermeneutic framework. Our task seemed much more focused now, but it could not have become so without the more decentralized process we underwent as part of our daily interdisciplinary encounter. Following our initial findings, the questions we have asked ourselves have been formulated slightly differently: How can the algorithmic reading be prevented from gaining too domineering a status? How can one avoid seeing it as having an epistemic value that enjoys superiority over the human ways of reading and interpreting?
5. Tools, not Miracle Devices: A Very Short Introduction for Non-Mathematicians
We will return to these questions and describe the unexpected direction in which the study led at a later point. Before that, and in order to allow a better understanding of this direction, we will try to describe and explain in simple terms the mathematical logic behind one of our main tools: the word-embedding word2vec model.28
So, then, how does it work? Human beings express their thoughts by giving them textual labels, such as words and phrases, or even by using physical objects (sculptures, buildings). This representation of a concept is what may be called a word meaning. In the field of textual computation, however, the meaning of words alone has limited application since in many cases their full nuanced meaning depends on the context in which they are used. While human beings have an innate capacity to adapt the meaning of a word according to the context in which it is being used, the computer simply does not have such innate capacity. More generally, linguistic concepts such as synonyms, antonyms, and hypernyms, go beyond the simple definition of a word’s meaning. Given this, teaching a computer to understand these concepts, is not a trivial task.
Early attempts at representing abstract concepts for a computer were based on discrete word representation via lexicons; a word would be linked to a list of words that relate to it in some sensical way. For example, ›beautiful‹ would be associated with the following list: [alluring, appealing, charming, cute, dazzling, good-looking]. The main drawback of such methods is that they do not consider the context in which the word is being used. Any word can take on a different meaning according to the context in which it is being used, such as in: »The sunlight was dazzling that morning in the French Riviera« or »The red-carpet dress she wore was dazzling«. In other words, the actual similarity between the words is not effectively represented merely by lists of similar words. This becomes problematic when one is trying to automatically make sense of a word or a phrase. One can completely misread the actual meaning of a word or sentence if the accompanying circumstances affecting nuances of meaning, such as situation or emotion, are not taken into consideration when establishing the relationship between a given set of words.
The problem of discrete word representation has led to the idea of distributed word representation. Every word is represented based on the meanings of the neighboring words in a specific corpus of text. For example: »The world of online education will become extremely relevant and significant for students who are looking to acquire new skills and get a world-class education from world-class teachers«. In this sentence, the word ›education‹ will be represented by its neighbouring words like ›online‹, ›students‹, ›teachers‹, ›skills‹, etc.
Word-embedding is an umbrella term for a host of various techniques that represent words as vectors of real value (the length of the vector is a parameter which one specifies). Instead of specifying the values for the embedding manually (as in the lexicon example), the vectors are trained from a corpus of texts (usually using a neural network algorithm), to satisfy a certain property. The typical property is that words that mean the same, and by »mean the same« we mean have similar neighbourhoods, will be assigned vectors with a small angle between them (or, large co-sine similarity).
The most common word-embedding techniques are word2vec and Glove.29 We will focus on word2vec which was developed by Tomas Mikolov of Google in 2013. Word2vec takes as its input a large corpus of texts and produces a vector space, typically of several hundred dimensions, with each unique word in the corpus being assigned a corresponding vector in the space, such that words that share common contexts in the corpus are located close to one another in the space (co-sine similarity).
We now outline how these vectors are learned from a textual corpus.30 The text is iterated over using a sliding window of size around a target word w (a parameter to be fixed). Let’s take the sentence »The black monkey went mad«, where the window of size d=2 and the target word is ›monkey‹. The task of the neural network is to predict the target word from the surrounding words. Broadly speaking, it does the following:
The input layer has V neurons, one for every word in the corpus, denoted by . The input at training is a one-hot encoding of the surrounding words.
Suppose that ›black‹ is then .
Similarly, the neurons corresponding to ›the‹, ›black‹, ›went‹, ›mad‹ are switched on, and all other neurons are set to zero.
The neurons are connected, in a fully connected manner, to a hidden layer of size N (N is the length of the vector embedding).
A successful outcome is, if the network was able to predict monkey when the four surrounding words were switched on.
The choice of this training schema will become clear shortly. The way the network speaks its prediction is by giving a number in [0,1] for each neuron at the output layer, which stands for the probability that this is the right word. At training time, the weights for the NN (Neural Network) are adjusted so that the probability of ›monkey‹ goes up and the probability of the other words goes down. This adjustment procedure is repeated many (many) times; the typical size of a training corpus contains millions of sentences (think of the entire English Wikipedia).
After the training step, the vectors are derived from the trained NN in the following manner: for every word , look at the N edges that connect it to the hidden layer. The vector of that word is the weights along these edges. We expect that words that appear in similar contexts will have close vectors since in order for similar inputs to produce similar outputs the weights need to be similar (the way the NN works).
The applications of word embedding in the real world are many and diverse. They include automatic translation, word completion, text understanding, detection of abusive speech, etc. Famous examples of word embedding arithmetic include words like ›men‹ and ›king‹, which may give the gender-less functionality of a ruler; adding this difference to ›women‹ may result in a ›queen‹. Similarly, one can derive verb inflections to find relationships like capital-city and country (i.e. the vector representation reveals the similarities between the duos ›Berlin‹ - ›Germany‹, ›Tokyo‹ - ›Japan‹, and ›Buenos Aires‹ - ›Argentina‹ - as well as the difference between them and other pairs of words).
How can all this be relevant for literary studies? In our research project, we take advantage of the word embedding philosophy to discover latent relationships between the characters of the novel.31 Traditionally, such a task was done either in a qualitative way, by reading the novel and using one’s own human faculties to say how character A relates to B. Later on, when digital humanities started gaining popularity, such tasks were performed by simple counting tricks: how many times A and B talk to each other, appear on the same page, etc. But the question of the symbolic essence of these interactions, could not be answered in this way. In this study, therefore, we are proposing a relatively new way of quantifying how A relates to B by training a word-embedding over the text of the novel, looking at the vectors of characters A and B, and then seeing how close the vectors are. If the two characters appear in similar contexts (say, they are both caregivers) then we expect their vectors to be close. And once we have a word-embedding of the novels’ characters, we can use it to extract more information; in the spirit of what was explained above, for example, we can ask if character A relates to B the same way C relates to D. Such relationships are latent, at least to the human eye, as we do not have the capacity to track down the context in which two characters appear (and most certainly not the entire set of pairs) throughout the novel. To this end, automated procedures, such as word embedding, exhibit a clear ability that human beings lack.
But as satisfying as the result may be, it cannot but be partial, as the results of other models have been. Taking this into account, we are proposing to look carefully at the data to be found in the discrepancy between word embedding and other methods, such as direct automatic counting, or even a reading-based manual one. Suppose that A and B appear together frequently on stage, but their vectors are almost perpendicular (no relationship). What does this tell us about A and B? Suppose that A and B rarely appear, but their vectors are very close. What does this tell us? In what follows, we will focus on this kind of information.
6. Towards Undogmatic Modelling
These last reflections relate closely to the updated research questions formulated earlier, which we will now repeat: How can the algorithmic reading be prevented from gaining too domineering a status? How can one avoid seeing it as having an epistemic value that enjoys superiority over the human ways of reading and interpreting?
A first general answer to these questions stems, we believe, from a necessary awareness of the very nature of models. Models, as the term implies, are a representation of a phenomenon – in our case, network graphs (designed as figures) that represent literary interactions (designed as words in a text) – which does not, and should not, totally overlap with the phenomenon itself. They are always based on the selecting and highlighting of certain aspects of the phenomenon, at the expense of others. As Meister, echoing Umberto Eco, puts it: there is no 1:1 ratio map;32 and as Willard McCarty formulated it, »models conceal when they reveal«.33 We use models, then, despite their disadvantages, because they are useful:34 They allow us to see things that are not sufficiently visible without their help. This is especially true for probabilistic models:35 The indication by the model of, for example, a relationship between two words or two topics in a corpus, does not necessarily mean that this relationship is realized in a corpus, but only that there is a high probability of such a realization, based on data that has been fed into the model.36
However, here we want to focus on a second answer to these questions, and a more specific one – one that derives from the concept of modeling formed in our work. Let’s say we asked a reader, or different readers, to rank the characters in a given novel in order of importance, and to turn that rating into a graph. Next, let’s assume that we computationally produced another graph, which ranks the same characters in the same novel according to the frequency of their appearance. These two graphs are two models of the novel; both focus on one aspect of it – the characters – and the weight to be attributed to each. But they both weigh it differently. Each of these graphs reveals and conceals at the same time: it illuminates a certain feature of the novel – importance or appearance – and prevents us from seeing another feature.
Now, what happens if we put these two graphs on top of each other? Given that each character has a measurable weight in each of the graphs, a computer program can easily calculate the ratio between the weights and produce a third weight: the ratio between narrative prominence and textual prominence. This weight, by definition, highlights the partial nature of each of the other forms of gaze. Equally important, this new metric tells something new about the poetics of that novel and can later allow for a cluster of different novels depending on how they are realized: that is, a cluster based on the distinction between novels where the most frequently mentioned characters are also the most significant ones, and novels where the most significant characters are, actually, the ones that are less frequently mentioned; whether because these are artistically experimental novels, or simply because they are narrated by a homodiegetic narrator (and therefore one whose name is remembered less, and who has a limited perspective on what is happening). In other words, this third model seems to tell the researcher – please note, in this and that novel, the first two models do not match one another; something poetically interesting might be happening there; you should take a look.
This is, in short, the basic idea that will guide us once the project has matured in its current direction. Instead of focusing on what can be described as a direct operationalization, which assumes a relationship of reflection – even if partial – between the measurement findings and the phenomenon being examined, we are proposing an undogmatic operationalization, based on three assumptions:
each model is partial, so it is especially worth noting the relationship between it and other models, especially when they do not match one another;
the most interesting phenomena may be precisely in these places, although there is of course no certainty that this will indeed be the case; and finally,
identifying and analyzing interesting passages is, and should be, a mission for human hermeneutics.
This idea is the concept that underlies TEASER, the product (and philosophy) of our ongoing joint project. TEASER, the abbreviation of Text Evaluation and Analysis based on Serial Readings, now under development,37 is designed to support just such an interpretive process: the system is serially fed38 with different models of text, some automatic, some manual. It calculates the relationship between them and produces a product that highlights points of mismatch between them, and which serves, therefore, as a teaser: Note, the system teases the researcher, something interesting may be happening here; I am not sure – it is not my role here – but I think it is worth checking.
This, in the end, is another way to move from algorithmic to human reading and vice versa.39 Mathematics is definitely integrated here in the interpretive process, in a series of measurements and measurements of measurements, and it reveals something that human reading alone cannot see. But the partial nature of its gaze is conceptually and technically marked and highlighted in a way that does not allow the researcher to repress it. On the contrary: it pushes the human researcher to re-read the text (or part of it) to see if indeed this textual ›MRI‹ is, actually, indicating something worth studying more closely. Although this reading is guided by the computer, the human-researcher is free to decide how to interpret and evaluate its limited findings.
7. Multi-layered Models in Practice
Let’s have a brief look at a few examples. As mentioned above, the topic that interested us in Amos Oz’s work was the relationships between characters. The accepted computational way in such cases, and which has already been accepted as a common method in digital humanities, is to represent the relationship through a network where each character is a node, which is linked to other nodes on some defined basis, depending on the researcher’s choice. Such a network, later on, can be mathematically analyzed using tools taken from graph theory, allowing for a deeper understanding of the dynamics between characters in a work or in a corpus of works.
To analyze Oz’s novels’ networks, we built several alternative networks for each novel: (1) a manual network based on a human reading of the novel and marking any communication between characters as a noteworthy connection; (2) an automatic network based on the mentioning of different characters in the same paragraph; and (3) an automated network based on similar semantic relationships between characters, as these are expressed in the word2vec model explained above in detail. Next, we placed the networks on top of one another – sometimes including the manual network, sometimes without it – and the results obtained were, indeed, in some cases, teasing.
Figure no. 1, for example, is a unified graph for networks in the novel ›A Perfect Peace‹ (1982; translated and published in English by Hillel Halkin in 1985), on which we will focus here. At first glance, the figure is similar to other illustrations of its kind. But in fact, this is a multi-layered network designed as a ›heat map‹: it is based on a measured comparison between the two automatic models mentioned above.
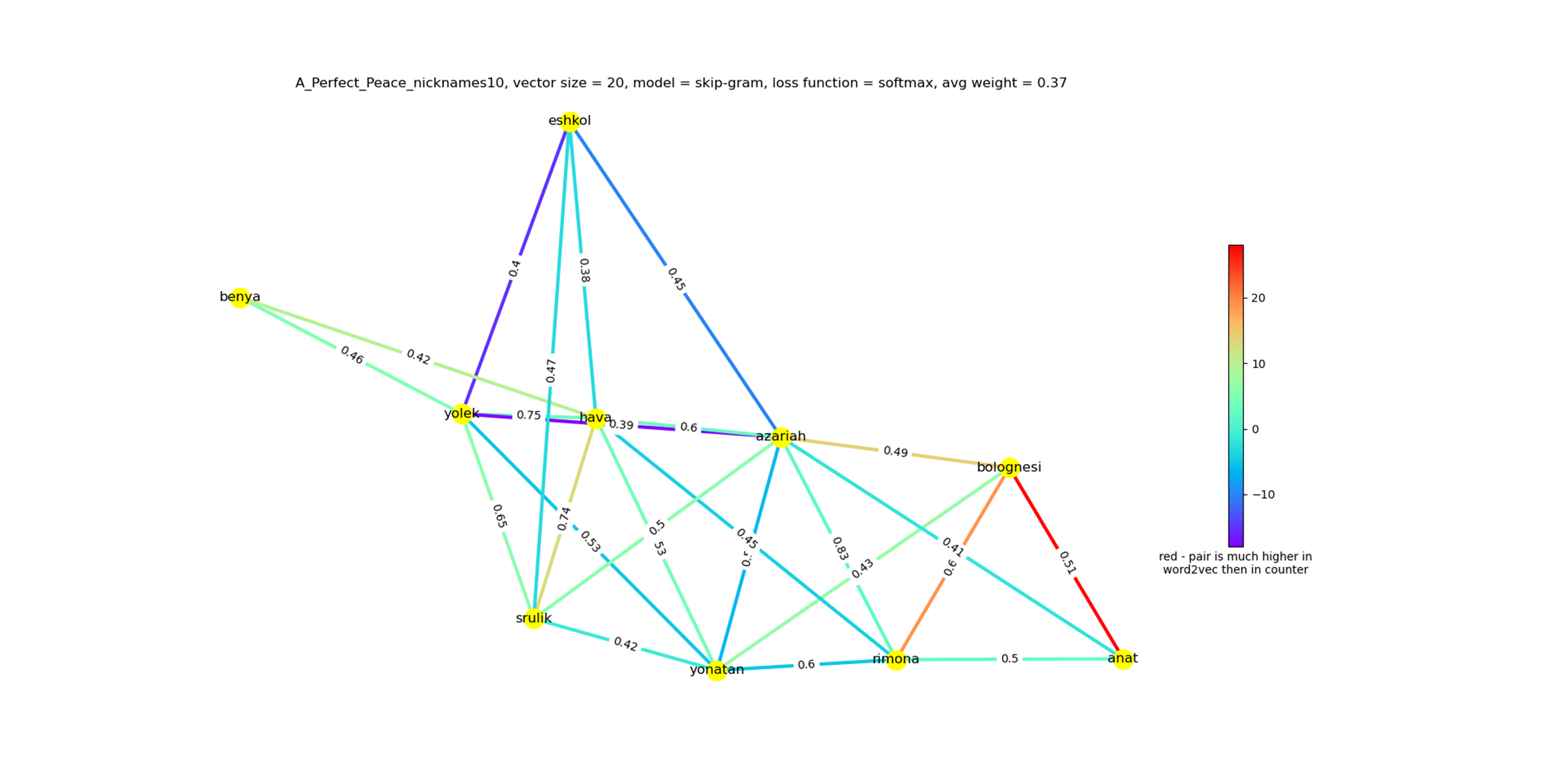 Figure no. 1. A unified graph for automatic network models of ›A Perfect Peace‹ by Amos Oz.
Figure no. 1. A unified graph for automatic network models of ›A Perfect Peace‹ by Amos Oz.
This heat map compares the relationship differences found by the two models: the redder the graph, the greater the gap between the semantic relationship that connects characters, as identified in the word2vec model, and the relationship based on their joint number of appearances (what we call ›the counter model‹). Or, in other words, these are characters who appear in a similar semantic field but do not tend to »get on stage« together in the novel scenes. On the other hand, the more the graph tends towards purple, the more the characters tend to appear together, while the semantic connection between them is low. The number that appears in the graph in the links that connect the characters indicates a measure of the strength of the relationship between them in the semantic model.40
Using this map, the researcher can identify two interesting areas: the first is a purple-blue triangle that includes connections between Yulek, Hava, Azaria and Eshkol, characters that appear together but the semantic connection between them is low. The map marks the main characters in the novel: appearing together, but each having a different and distinct role in advancing the plot. The second area is orange-red lines coming out of Bolognesi to different characters, Azaria, Rimona, and Anat. Bolognesi, a minor character who almost never appears in the novel, is revealed to have a strong semantic connection to the main characters (Azaria and Rimona) and another secondary character (Anat). This marking signals the interpreter to return to the text and to try and understand in what exact way (on the plot level? Or maybe on a more symbolical level?) the character of Bolognesi connects in a similar way various characters, and how he advances the plot, despite his weak presence in the text.
Figure no. 2 continues by comparing the two computational models for this novel, but in a different way (admittedly, a less intuitive one).
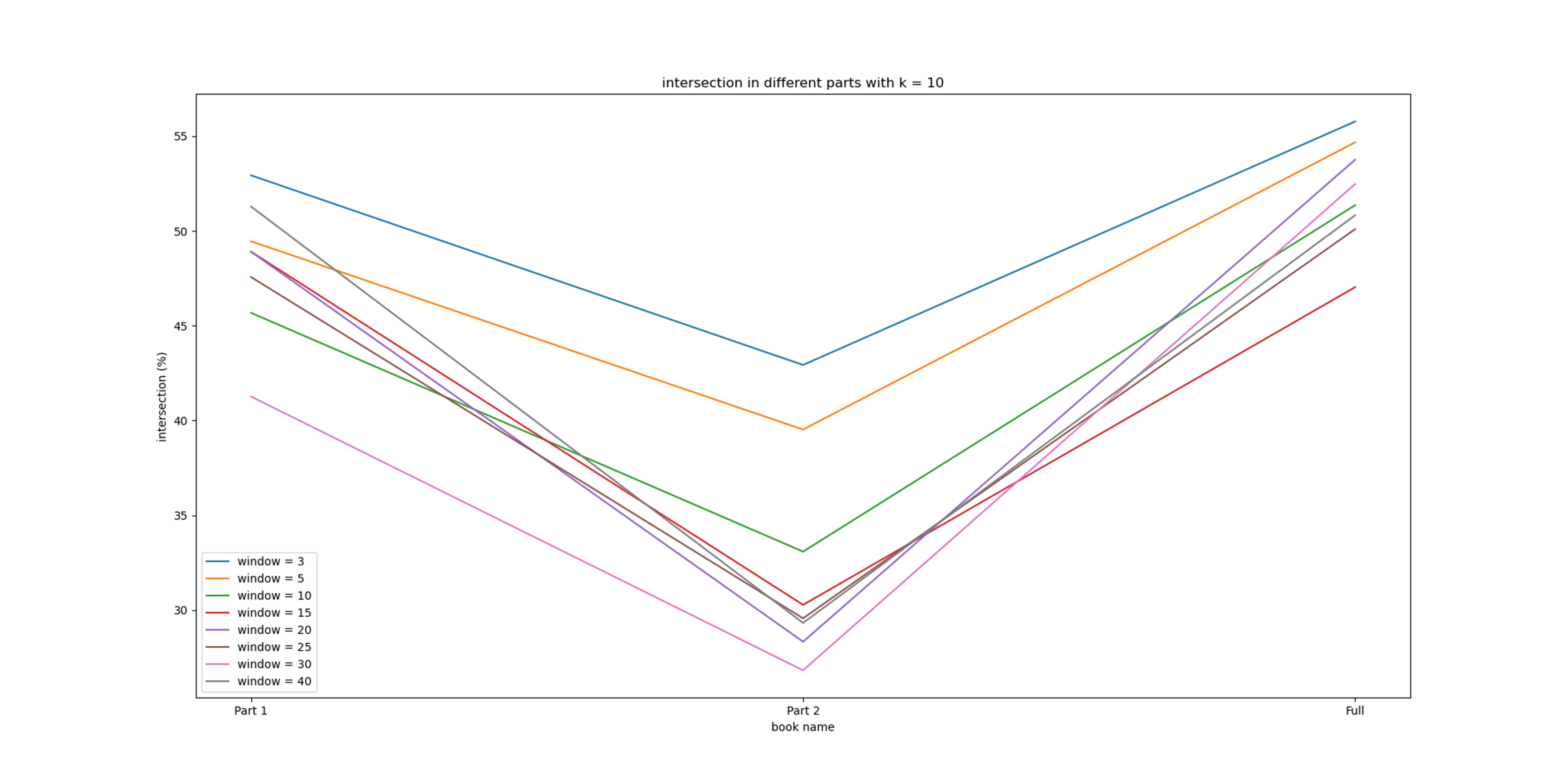 Figure no. 2. Degrees of overlap between two automatic models of the novel, which represent strong relationship between pairs of characters, along different parts of the novel.
Figure no. 2. Degrees of overlap between two automatic models of the novel, which represent strong relationship between pairs of characters, along different parts of the novel.
This figure represents the number of pairs of characters (K) with the strongest relationship in both models. That is, if K = 10 then the analysis will focus on the ten pairs of characters identified with the strongest relationship after combining the two models. The diagram examines the degree of overlap between these ten pairs between the two models, in light of the different parts of the novel. It can be seen that the results show a clear trend: regardless of the size of the vector window selected for the word2vec algorithm, the degree of overlap between the models is lower in the second part of the novel (as seen in the middle of the figure) than in the first part (on the left side of the figure) or in the whole novel (on the right side). The diagram thus marks the second part of the novel as the most important or interesting part in terms of plot: this is the part where the characterization of the characters sharpens, in which they are given different roles in terms of plot. Indeed, in the case of this novel, in the first part, the characters are together in the kibbutz environment, while in the second part the main character in the novel, Yonatan, leaves the kibbutz and the other characters face the question of how and whether he will return.
Figure no. 3 allows another look at the differences between the models while integrating the manual network model this time.
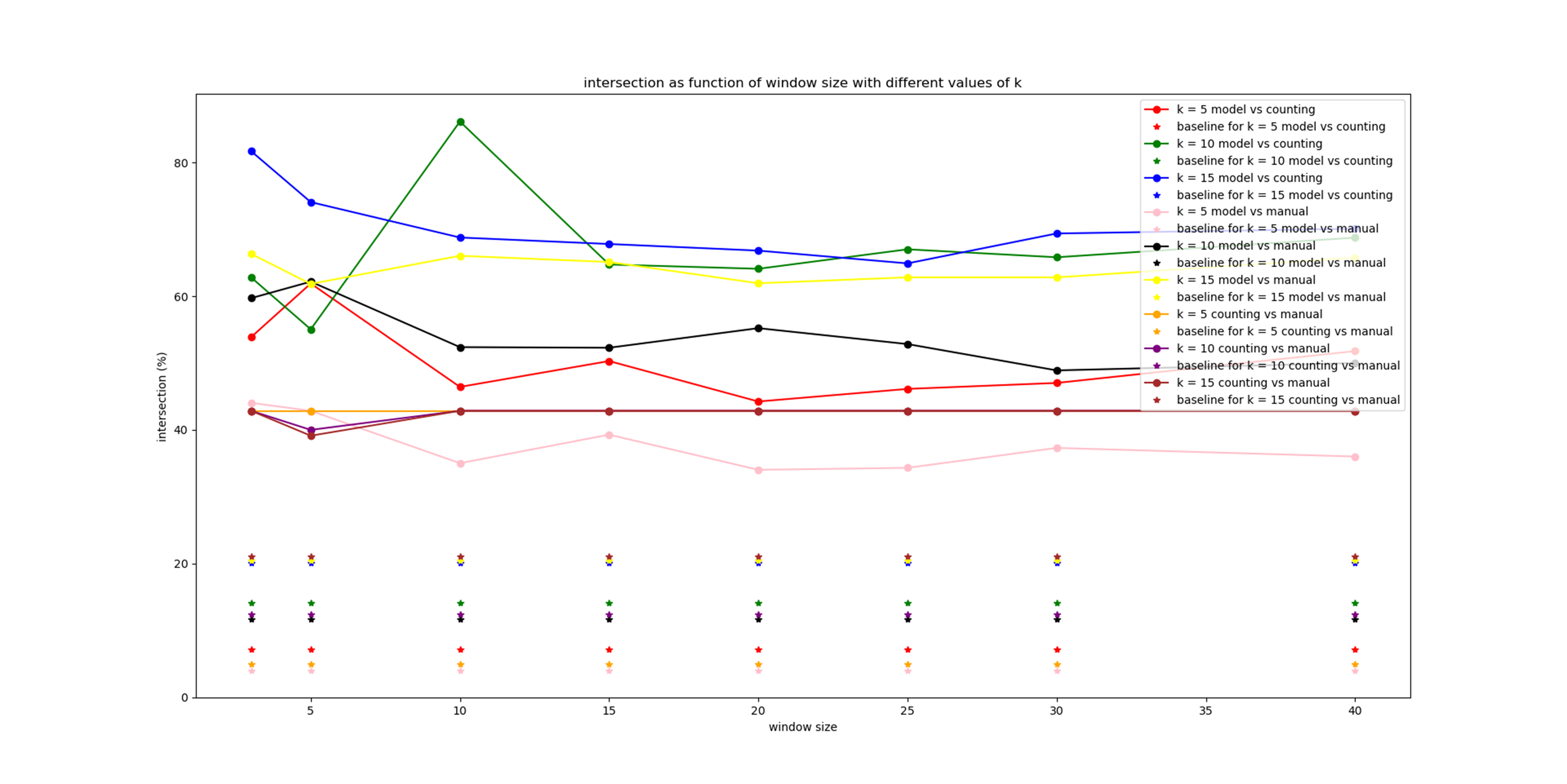 Figure no. 3. Differences between the three network models of the novel.
Figure no. 3. Differences between the three network models of the novel.
The red, green, and blue lines compare the Counter model and the word2vec model. It can be seen in this graph that the general trend is that the larger the K size – that is, the larger the number of character pairs under examination – the greater the overlap between the models, almost regardless of the window size (except for the unexplained jump in the green window 10 window size). The relatively significant difference between K = 5 and k = 10 again strengthens the assumption that the gap between the models is more interesting when we examine the closest pairs in them.
The pink, black and yellow lines compare the word2vec model with the manual model. Here one can see relatively clearly the difference between the models: the smaller the K, the more differentiated the models. On average the graphs of the two types of comparisons (the average of the red, green, and blue graph versus the average of the black and yellow pink graph), the counter model, and the word2vec model appear to be less different from each other than the word2vec and the manual model.
However, when comparing the two models based on a joint appearance of characters, Counter vs Manual, it seems that the merging of the lines that represent it (purple-orange and burgundy), shows an almost complete match in the overlap between the models. So, on the one hand, this result reflects the fact that a shared basic guideline underlies these two models, which are in any case based on the textual closeness between characters; but on the other hand, it challenges a bit the assumption that human reading necessarily adds significant information for comparison between these models. This ambiguity, of course, can be examined in the light of another human reading, alongside further computerized analysis. In this way, the relationship between computerized reading and human reading is shaped as a kind of playful and dialectical negotiation.
These three examples, of course, are just an appetizer for a teaser: a system that compares various textual models, whatever they may be, in order to use them to mark speculations of points of interest for the human researcher. Admittedly, this is a relatively modest appetizer. The concept proposed here can theoretically be realized as well as tested in other novels and with various forms of computational modeling of literary texts, which are far beyond the limits of this article. Measurement in literature and literary theory is a complicated matter, and our proposal does not make it any less complicated. We hope to extend our experiments in the future to other forms of textual operationalizing as well.41
8. Conclusions: or, on the Comparison of Apples and Oranges
As we have seen, it is not enough to focus on measurement. The question is not only what to measure, how to measure, and what measurement means, but also, what the relationship between different measurements is. This relationship can be calculated, and the result can be represented numerically or visually. The result is especially interesting when it reveals discrepancies between different measurements. It does not necessarily function as a naïve direct answer to a given question, but as a teaser, as food for thought. The undogmatic modeling approach described here, therefore, might contribute not only to the validation of the computational model for literary study42 but also to the understanding of the special hermeneutic potential found in highlighting differences between models. It treats them as potential markers of literary points of interest, which are interesting because they are derived from an encounter between alternative perspectives – mathematically-oriented and literary-oriented – and because they illustrate the multidimensionality inherent in the literary text.
Of course, as is always true in comparisons, it is important to compare models that have one thing at least in common; but at the same time, one should not necessarily avoid comparing models that seem, at first and even at second glance, farther apart. If a model is a map of a text, then, as long as two different geographic maps (economic, topographic, climatic, etc.) describe the same area – in our case, the same novel – the interrelationships between them may be striking. The keywords here are »may be«: our system, based on defamiliarization of operationalization, guarantees nothing but a complex and thought-provoking connection between words and numbers; the conclusions that can be drawn from this connection, after all, are a matter of human interpretation.
Bibliography
AIDEN-LIEBERMAN, Erez a. Jan-Baptiste Michel: Uncharted: Big-Data as a Lens on Human Culture. New York 2013.
ALON, Uri: »How to Choose a Good Scientific Problem«. Molecular Cell 35 .6 (2009), pp. 726–728. DOI: 10.1016/j.molcel.2009.09.013.
AUERBACH, Erich: »Philology and Weltliteratur«. Translated by Maire Said a. Edward Said. In: The Centennial Review 13.1 (1969), pp. 1–17.
BALABAN, Avraham: »Oz (Klausner), Amos«. In: Zissi Stavi a. Yigal Schwartz (eds.): The Heksherim Lexicon of Israeli Authors (in Hebrew). Or Yehuda / Beer-Sheva 2014, pp. 685–688.
BOX, George E. P a. Norman Richard Draper: Empirical Model-Building and Response Surfaces. New York 1989.
BRIDGMAN, Percy Williams: The Logic of modern physics. New York 1927.
DA, Nan Z.: »The Computational Case against Computational Literary Studies«. In: Critical Inquiry 45 (2019), pp. 601–639.
EVE, Martine Paul: Close Reading with Computers: Textual Scholarship, Computational Formalism, and David Mitchell’s Cloud Atlas. Stanford 2019.
FLANDERS, Julia a. Fotis Jannidis(eds.): The Shape of Data in Digital Humanites: Modeling Texts and Text-Based Resources. London / New York 2019.
FLÜH, Marie, Jan Horstmann, Janina Jacke a. Mareike Schumacher »Introduction: Undogmatic Reading – from Narratology to Digital Humanities and Back«. In: Marie Flüh, Jan Horstmann, Janina Jacke a. Mareike Schumacher (eds.): Toward Undogmatic Reading: Narratology, Digital Humanities and Beyond. Hamburg 2021.
GIUS, Evelyn: »Narration and Escalation. An Empirical Study of Conflict Narratives«. In: DIEGESIS. Interdisciplinary E-Journal for Narrative Re-search / Interdisziplinäres E-Journal für Erzählforschung 5.1 (2016), pp. 4–25.
HAMMOND, Adam: »The double bind of validation: distant reading and the digital humanities’ ›trough of disillusionment‹«. In: Literature Compass 14.8 (2017). DOI: 10.1111/lic3.12402.
HORSTMANN, Jan: »Undogmatic Literary Annotation with CATMA: Manual, Semi-automatic and Automated«. In: Julia Nantke a. Frederik Schlupkothen (eds.): Annotations in Scholarly Edition and Research. Berlin / Boston 2020, pp. 157–175.
JANNIDIS, Fotis: »On the Perceived Complexity of Literature. A Response to Nan Z. Da«. In: Journal of Cultural Analytics 5.1 (2020).
JUOLA, Patrick and Stephen Ramsay: Six Septembers: Mathematics for the Humanities. Lincoln 2017.
MANOVICH, Lev: Cultural Analytics. Cambridge/MA / London 2020.
MARIENBERG-MILIKOWSKY, Itay: »Beyond Digitization: Digital Humanities and the Case of Hebrew Literature«. In: Digital Scholarship in the Humanities 34.4 (2019), pp. 908–913.
MARIENBERG-MILIKOWSKY, Itay: »The Nurturing Digital Humanities Lab: An Inside Perspective«. In: Christopher Thomson and Urszula Pawlicka Deger (eds.): Digital Humanities Laboratories. Forthcoming.
MCCARTY, Willard: Humanities Computing. Basingstoke 2005.
MEISTER, Jan Christoph: »Computerphilologie vs. Digital Text Studies. Von der pragmatischen zur methodologischen Perspektive auf die Digitalisierung der Literaturwissenschaften«. In: Christine Grond-Rigler a. Wolfgang Straub (eds.):Literatur und Digitalisierung. Berlin / Boston 2013, pp. 267–296.
MEISTER, Jan Christoph: »Toward a Computational Narratology«. In: Agosti Maristella and Tomasi Francesca (eds.): Collaborative Research Practices and Shared Infrastructures for Humanities Computing. Padova 2014, pp. 17–36
MEISTER, Jan Christoph: »From TACT to CATMA or A mindful approach to text annotation and analysis«. In: Julianne Nyhan, Geoffrey Rockwell a. Stéfan Sinclair (eds.): On Making in the Digital Humanities: Essays on the Scholarship of Digital Humanities Development in Honour of John Bradley. Forthcoming.
MORETTI, Franco: »Conjectures on World Literature«. In: New Left Review 1 (2000), pp. 54–68.
MORETTI, Franco: Distant Reading. London / New York 2013.
MORETTI, Franco: »Operationalizing: or, the Function of Measurement in Modern Literary Theory«. In: Stanford Literary Lab Pamphlets 6 (2013).
MORETTI, Franco: »The Slaughterhouse of Literature«. In: Modern Language Quarterly 61.1 (2000), pp. 207–227.
OREKHOV, Boris and Frank Fischer: »Neural Reading: Insights from the Analysis of Poetry Generated by Artificial Neural Networks«. In: Orbis Litterarum 75.5 (2020), pp. 230–246. DOI: 10.1111/oli.12274.
OZ, Amos: A Perfect Peace. Translated by Hillel Halkin. San Diego/CA 1985.
RYBICKI, Jan, et al. »Harper Lee and Other People: A Stylometric Diagnosis«. In: The Mississippi Quarterly 70–71.3 (2017).
ROCKWELL, Geoffrey and Sinclair, Stéfan: Hermeneutica: Computer-Assisted Interpretation in the Humanities. Cambridge/MA / London 2016.
UNDERWOOD, Ted, Distant Horizons: Digital Evidence and Literary Change. Chicago 2018.
WITTIG, Susan: »The Computer and the Concept of Text«. In: Computers and the Humanities 11.4 (1977), pp. 211–215.
- 1. * This research was generously supported in part by a special research grant from the Vice President for Research and Development at Ben-Gurion University of the Negev, and in part by grant No. 1223 from the Israeli Ministry of Science and Technology. We would like to thank the editors of this special issue, Jan Horstmann and Frank Fischer, as well as Gulşin Çiftçi and Jan Rybicki, for their insightful comments, which helped us to significantly improve this paper.
1 Franco Moretti: »Operationalizing: or, the function of measurement in modern literary theory«. In: Stanford Literary Lab pamphlets 6 (2013), p. 13.
- 2. Nan Z. Da: »The Computational Case against Computational Literary Studies«. In: Critical Inquiry 45 (2019), pp. 601–639. A collection of responses to Da’s article was published in the debate section of the Journal of Cultural Analytics: https://culturalanalytics.org/section/1580-debates (accessed October 10, 2021). We will return to one of these responses towards the end of the article.
- 3. Franco Moretti: »Operationalizing: or, the function of measurement in modern literary theory«. In: Stanford Literary Lab pamphlets 6 (2013), p. 1.
- 4. Moretti: »Operationalizing« (ref 1), p. 1.
- 5. Franco Moretti: »Conjectures on World Literature«. In: New Left Review 1 (2000), pp. 54–68. See also another article from the same year in which he called for anarchy in the study of literature: Franco Moretti: »The Slaughterhouse of Literature«. In: Modern Language Quarterly 61.1 (2000), pp. 207–227.
- 6. Moretti: »Operationalizing« (ref. 1), p. 13.
- 7. Computers are not mentioned at all even in his 2000 article mentioned above, which interestingly became a kind of manifesto of digital humanities; but this article was indeed written before Moretti began the digital phase of his research. Therefore, the purely instrumental attitude to them in the 2014 article, when the author headed the Stanford Literary Lab, seems even more principled.
- 8. Evelyn Gius: »Narration and Escalation. An Empirical Study of Conflict Narratives«. In: DIEGESIS. Interdisciplinary E-Journal for Narrative Research / Interdisziplinäres E-Journal für Erzählforschung 5. 1 (2016), p. 10.
- 9. Erez Aiden-Lieberman a. Jan-Baptiste Michel: Uncharted: Big-Data as a Lens on Human Culture. New York 2013.
- 10. Lev Manovich: Cultural Analytics. Cambridge/MA / London 2020.
- 11. Geoffrey Rockwell a. Stéfan Sinclair: Hermeneutica: Computer-Assisted Interpretation in the Humanities. Cambridge/MA / London 2016.
- 12. See, for example: Martine Paul Eve: Close Reading with Computers: Textual Scholarship, Computational Formalism, and David Mitchell’s Cloud Atlas. Stanford 2019.
- 13. See, for example: Jan Christoph Meister: »Computerphilologie vs. Digital Text Studies. Von der pragmatischen zur methodologischen Perspektive auf die Digitalisierung der Literaturwissenschaften«. In: Christine Grond-Rigler a. Wolfgang Straub (eds.): Literatur und Digitalisierung. Berlin / Boston 2013, pp. 267–296; Jan Christoph Meister: »Toward a Computational Narratology«. In: Agosti Maristella a. Tomasi Francesca (eds.): Collaborative Research Practices and Shared Infrastructures for Humanities Computing. Padova 2014, pp. 17–36; Jan Christoph Meister: »From TACT to CATMA or A mindful approach to text annotation and analysis« In: Julianne Nyhan, Geoffrey Rockwell a. Stéfan Sinclair (eds.): On Making in the Digital Humanities: Essays on the Scholarship of Digital Humanities Development in Honour of John Bradley. Forthcoming.
- 14. Meister: »Computerphilologievs. Digital Text Studies« (ref. 15), p. 295, as translated into English by Marie Flüh et al. »Introduction: Undogmatic Reading – from Narratology to Digital Humanities and Back«. In: Marie Flüh, Jan Horstmann, Janina Jacke a. Mareike Schumacher (eds.): Toward Undogmatic Reading: Narratology, Digital Humanities and Beyond. Hamburg 2021. It is no coincidence that this passage echoes a relatively frequently quoted passage by Susan Wittig, who as early as 1977 expressed frustration at the gap between the computational conception of the text, and its human conception, as shaped in those years by post-structuralism and the reader-response school: Susan Wittig: »The Computer and the Concept of Text«. In: Computers and the Humanities 11.4 (1977), pp. 211–215.
- 15. https://catma.de. See: Evelyn Gius et al. (2021): CATMA 6 (Version 6.3). Zenodo. DOI: 10.5281/zenodo.1470118
- 16. Meister: »Toward a Computational Narratology« (ref. 15), p. 29.
- 17. Jan Horstmann: »Undogmatic Literary Annotation with CATMA: Manual, Semi-automatic and Automated«. In: Julia Nantke a. Frederik Schlupkothen (eds.): Annotations in Scholarly Edition and Research. Berlin / Boston 2020, p. 163.
- 18. Interestingly, CATMA includes, in addition to all of the above, a few machine-based components, and relies on the tools of computational linguistics, which allow the user to automatically annotate certain elements of texts in the German language. However, this option is only available to German textual scholars. For a full description of the tool see Horstmann: » Undogmatic Literary Annotation with CATMA« (ref. 19); for more technical details see CATMA website.
- 19. The origin of this term is in the Babylonian Talmud, an influential text composed in the 3rd-7th centuries AD. Linguistically it is derived from the root ch.v.r (ח.ב.ר), which is the building block of words whose meanings are friend, friendship, and the like.
- 20. Perhaps it is not inconceivable to imagine the not-so-distant day, when computational tools will indeed be able to ask us questions about our research, considering for example the achievements of the IBM Project Debater (https://research.ibm.com/interactive/project-debater/) (accessed October 6, 2021). What will be the meaning of a dialogue with an identity-less entity – that is a different question.
- 21. In general, the importance of mathematics to digital humanities seems to have gained increasing recognition in the last decade, with many researchers making it clear that, no less than literature, students need to acquire programming literacy, and also mathematical literacy. See, for example: Juola, Patrick a. Ramsay, Stephen: Six Septembers: Mathematics for the Humanities. Lincoln 2017.
- 22. Avraham Balaban: »Oz (Klausner), Amos«. In: Zissi Stavi a. Yigal Schwartz (eds.): The Heksherim Lexicon of Israeli Authors (in Hebrew). Or Yehuda / Beer-Sheva 2014, pp. 685–688.
- 23. This method is quite common in computational literary studies. An example of it can be found in Moretti’s 2013 article mentioned above.
- 24. These two writers lived at around the same time and put together a very broad corpus, one that is the result of an unconventional creative productivity spread over a very long period of time: Oz published 27 books of prose from 1965 to 2014; Appelfeld published 49 books of prose from 1962 to 2014. Against this background, we estimated that the scope of the corpus and its internal diversity promised at least partial success, indicating differences on the level of poetic complexity of different texts in the corpus – as well as differences in mathematical analysis applied to the various texts.
- 25. Itay Marienberg-Milikowsky: »Beyond Digitization: Digital Humanities and the Case of Hebrew Literature«. In: Digital Scholarship in the Humanities 34.4 (2019), pp. 908–913.
- 26. Apart from that, it sheds light on a field of study whose importance stands for itself – translated Hebrew literature – and provides a particularly fascinating test case for the use of computational tools in a multilingual context.
- 27. This is, actually, a usual process for the development of research. See: Uri Alon: »How to Choose a Good Scientific Problem«. In: Molecular Cell 35.6 (2009), pp. 726–728. DOI: 10.1016/j.molcel.2009.09.013. Such twists and turns are even more typical of joint and interdisciplinary studies, in which each party brings a different set of knowledge, assumptions and aspirations. Recognizing it is especially important, in our opinion, for projects in the digital humanities, and should have an impact on the design of laboratories and other research centers that provide such projects with an institutional framework. See: Itay Marienberg-Milikovsky: »The Nurturing Digital Humanities Lab: An Inside Perspective«. In: Christopher Thomson a. Urszula Pawlicka Deger (eds.): Digital Humanities Laboratories. Forthcoming.
- 28. It should be noted, that in terms of programming capabilities and mathematical knowledge, the use of such models is far more relatively complex than most humanities researchers are capable of – and therefore the number of researchers who use them is relatively small.
- 29. Recently, other types of embedding were introduced, e.g., BERT, but their description goes beyond the scope of this paper.
- 30. For another explanation of this technique (used in a different textual context), see: Boris Orekhov a. Frank Fischer: »Neural Reading: Insights from the Analysis of Poetry Generated by Artificial Neural Networks«. In: Orbis Litterarum 75.5 (2020), pp. 230–246.
- 31. This is made possible, inter alia, thanks to Book NLP - a common pipeline of natural language processing, developed by David Bamman (https://github.com/booknlp/booknlp), which allows a thorough preparation of long English texts for analysis. This pipeline is already integrated in computational literary studies. See, for example: Ted Underwood: Distant Horizons: Digital Evidence and Literary Change. Chicago 2018, pp. 111–142.
- 32. Jan Christoph Meister: »Toward a Computational Narratology«. In: Agosti Maristella a. Tomasi Francesca (eds.): Collaborative Research Practices and Shared Infrastructures for Humanities Computing. Padova 2014, p. 22.
- 33. Willard McCarty: Humanities Computing. Basingstoke 2005.
- 34. George E. P. Box a. Norman Richard Draper: Empirical Model-Building and Response Surfaces. New York 1989.
- 35. Unfortunately, an in-depth understanding of the significance of the probabilistic dimension in humanistic research in general and digital humanities in particular still lacks satisfying theorization. However, knowledge about models in the service of digital humanities has increased significantly. See: Julia Flanders and Fotis Jannidis (eds.): The Shape of Data in Digital Humanites: Modeling Texts and Text-Based Resources. London / New York 2019.
- 36. This is similar to throwing dice: although a simple mathematical analysis shows that in rolling two dice the greatest odds are that they will add up to 7 or 8, this does not necessarily mean that they will. In real time, one of the players may well throw dice over and over again that add up to 2, 3, 11, or 12.
- 37. As of now (February 2022), an alpha version is already in the process of checking and improving. We plan to release a beta version by the end of 2022.
- 38. According to Moretti in his 2013 programmatic book, the term ›distant reading‹ was born only in the last drafts of the 2000 article, and as a pun with known meaning, while the initial term used in the article was ›serial reading‹. We believe that the renewed emphasis on mathematical perspective goes hand in hand with seriality, rather than an image of distance.
- 39. ›Human reading‹ and not ›close reading‹ in the ordinary sense of the term, because the human reading described here is nevertheless directed by computer, and therefore does not reflect the full richness and hermeneutical potential normally attributed to close reading in its traditional form.
- 40. This graph only shows relationships between characters that exceed the average strength for the relationship between characters in the model of this novel, which stands at 0.37.
- 41. It is quite possible that the declared speculative dimension of our work, particularly in its present initial stage, will not succeed in overcoming such doubts as Da noted in her article mentioned above. However, our perception of the relationship between measurement and interpretation is different from her perception. And having said all that, we believe that expanding our experiment and validating it – for example, by completing the development of the TEASER tool that will serve the research community – will make it possible to place our proposal on solid ground. It should also be noted that it is no coincidence that Da focused on a particular group of CLS researchers, ignoring many others, some of whose work often stanfds indeed on more solid, empirical ground, and does not necessarily present itself as revolutionary in relation to traditional approaches. A good example of this can be found in: Jan Rybicki et al. »Harper Lee and Other People: A Stylometric Diagnosis«. In: The Mississippi Quarterly 70–71. 3 (2017). Our proposal, however, can in principle be tailored to a wide range of models, more or less solid. For a broader criticism about the limited perspective of Da, See also Jannidis, Fotis: »On the Perceived Complexity of Literature. A Response to Nan Z. Da«. In: Journal of Cultural Analytics 5.1 (2020), p. 10.
- 42. On the importance of validation in the digital humanities see: Hammond, Adam: »The double bind of validation: distant reading and the digital humanities’ ›trough of disillusionment‹«. In: Literature Compass 14.8 (2017). DOI: 10.1111/lic3.12402.

